Project Overview
This project proposes a joint optimization scheme for camera poses and 3D scene reconstruction using multi-resolution hash encoding. The core problem is that Instant-NGP-style hash grids accelerate NeRF training, but their grid-wise interpolation can create unstable gradients when camera poses are optimized together with the scene representation.
We observed that the oscillating gradient flows inherent to hash encoding interfere with accurate camera pose registration. To address this, we introduced smooth interpolation weighting to stabilize ray-sampled gradient propagation across hash grids. The method also uses curriculum-style level-wise learning, improving both camera pose refinement and novel-view synthesis quality.
Key Contributions:
- Proposed camera pose refinement for hash-grid NeRF training.
- Analyzed gradient instability caused by multi-resolution hash encoding during pose optimization.
- Introduced smooth-gradient interpolation and straight-through weighting for stable SE(3) updates.
- Improved pose refinement while retaining Instant-NGP's fast convergence profile.
Project Details
- Role: Research Lead, Camera Pose Optimization
- Category: Research, Neural Rendering, Camera Pose Estimation
- Publication: ICML 2023
- Organization: NAVER AI Lab, Korea University
- Technology: NeRF, Instant-NGP, Hash Encoding, SE(3) Optimization
- Paper URL: ACM DL
Method
Multi-Resolution Hash Encoding
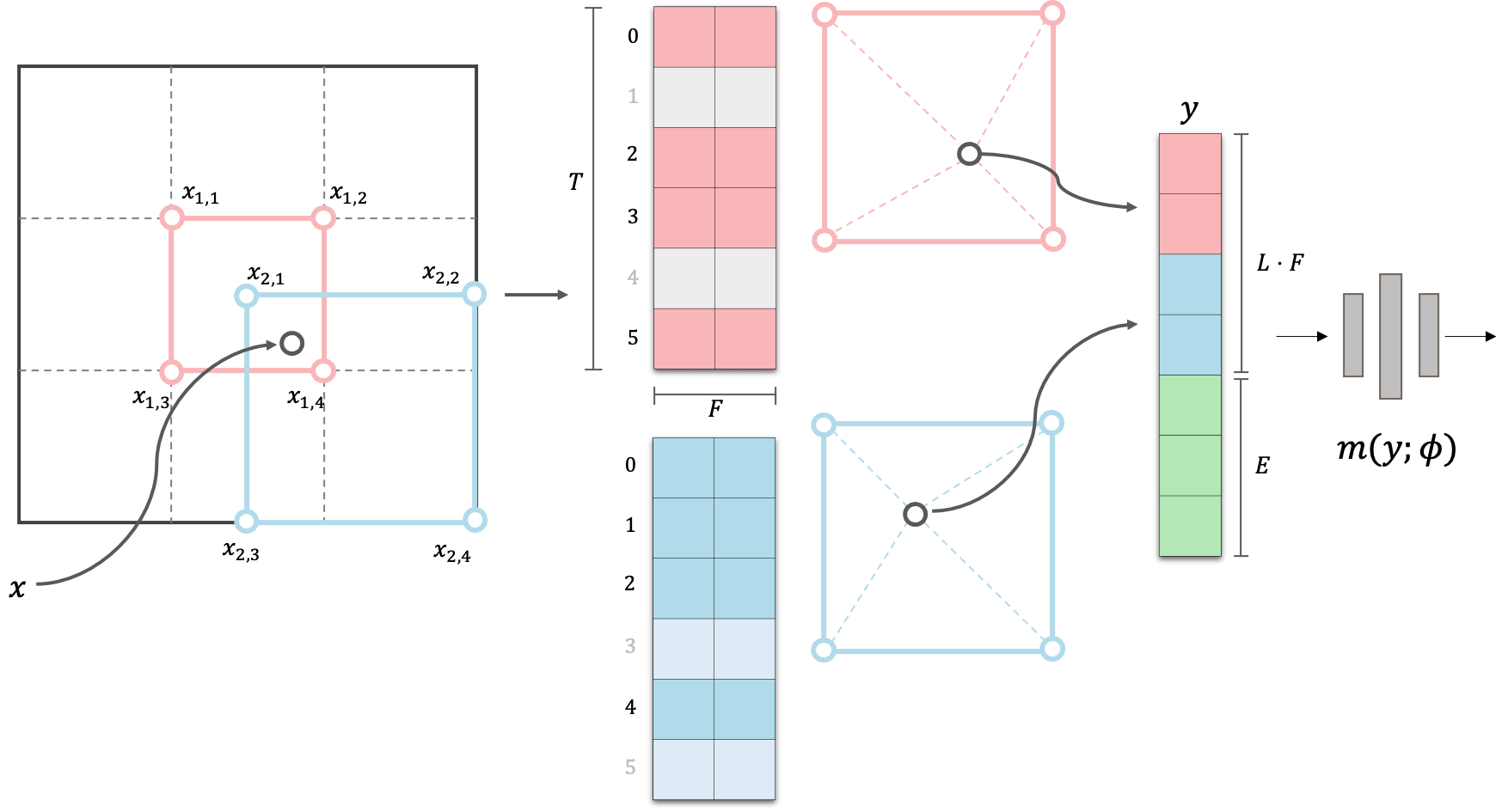
- A positional encoding uses the hash tables for multi-resolution features.
- Each feature is the tri-linear interpolation of the eight-corner entries in a grid cube using proportional weights depending on the location of a given point.
- Cannot back-propagate through the hash entries due to random hashing, but through the weights, where the gradients are discontinuous across the grids.
Pros. faster convergence with better accuracy
Cons. back-propagation through ray-sampled positions is unstable!
Smooth gradients for unstable back-propagation
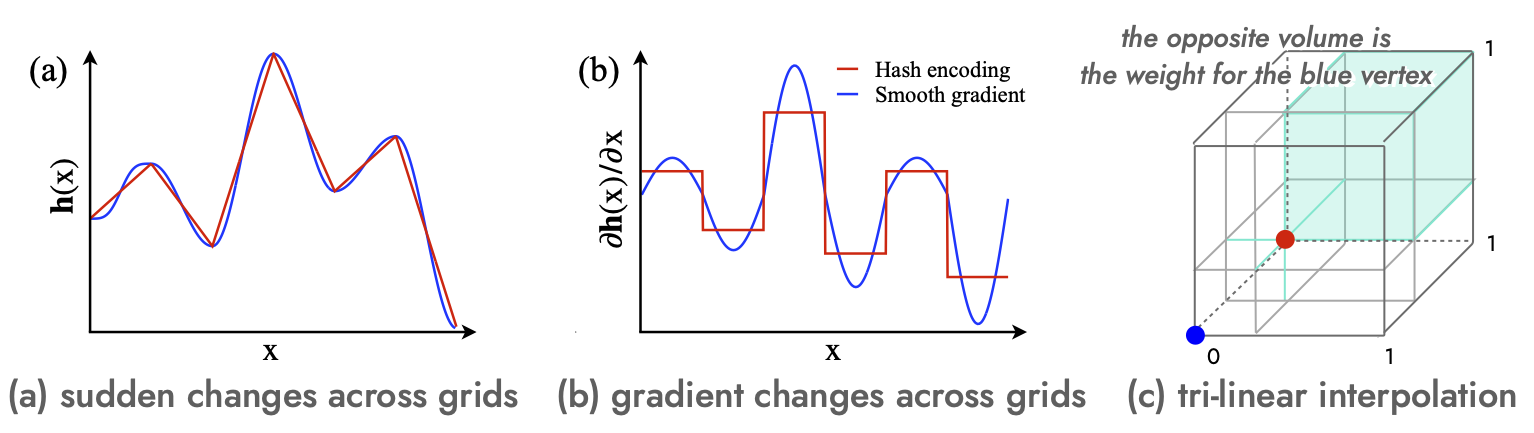
The Derivative of Multi-Resolution Hash Encoding
Using this relation and the appropriate choice of the indices, the $k^{\text{th}}$ element of Jacobian $\nabla_{\mathbf{x}}\mathbf{h}_{l}(\mathbf{x})$ can be rewritten as follows:
$$\begin{aligned} \nabla_{\mathbf{x}}\mathbf{h}_{l}(\mathbf{x}) &= \left[ \frac{\partial {\mathbf{h}_{l}}(\mathbf{x})}{\partial {x}_1}, \dots, \frac{\partial {\mathbf{h}_{l}}(\mathbf{x})}{\partial {x}_d} \right] \\ &= \sum_{i=1}^{2^{d}} \mathcal{H}_{l}\big( h_{l} \big( \mathbf{c}_{i,l} (\mathbf{x}) \big) \big) \cdot \left[ \frac{\partial {{w}_{i,l}}(\mathbf{x})}{\partial {x}_1}, \dots, \frac{\partial {{w}_{i,l}}(\mathbf{x})}{\partial {x}_d} \right]. \end{aligned}$$
Let $\bar{i}$ be one of the nearest corner indices from $\mathbf{c}_{i,l}$ in a unit hypercube, where $\mathbf{c}_{i,l}$ and $\mathbf{c}_{\bar{i},l}$ make an edge of the unit hypercube. Among the $2^d$ corners, we have $2^{d-1}$ pairs like that. Then, we have the relation for $w_{\bar{i}_k,l}$ as follows:
$$ \begin{aligned} \frac{\partial {{w}_{\bar{i}_k,l}}(\mathbf{x})}{\partial {x}_k} = - \frac{\partial {{w}_{i,l}}(\mathbf{x})}{\partial {x}_k}, \end{aligned}$$
which can be inferred from weight definition, since the relative positions of $\mathbf{x}$ are different for the two cases.
Using this relation and the appropriate choice of the indices, the $k^{\text{th}}$ element of Jacobian $\nabla_{\mathbf{x}}\mathbf{h}_{l}(\mathbf{x})$ can be rewritten as follows:
$$ \begin{aligned} \frac{\partial {\mathbf{h}_{l}}(\mathbf{x})}{\partial {x}_k} &= \sum_{i=1}^{2^{d}} \mathcal{H}_{l}\big( h_{l} \big( \mathbf{c}_{i,l} (\mathbf{x}) \big) \big) \cdot \frac{\partial {{w}_{i,l}}(\mathbf{x})}{\partial {x}_k} \\ &= \sum_{i=1}^{2^{d-1}} \left( \mathcal{H}_{l}\big( h_{l} \big( \mathbf{c}_{i,l} (\mathbf{x}) \big) \big) - \mathcal{H}_{l}\big( h_{l} \big( \mathbf{c}_{\bar{i}_k,l} (\mathbf{x}) \big) \big) \right) \cdot \frac{\partial {{w}_{i,l}}(\mathbf{x})}{\partial {x}_k} \\ &= \sum_{i=1}^{2^{d-1}} \left( \mathcal{H}_{l}\big( h_{l} \big( \mathbf{c}_{i,l} (\mathbf{x}) \big) \big) - \mathcal{H}_{l}\big( h_{l} \big( \mathbf{c}_{\bar{i}_k,l} (\mathbf{x}) \big) \big) \right) \cdot \prod_{j \neq k} \left( 1 - | \mathbf{x}_{l} - \mathbf{c}_{i,l}(\mathbf{x}) |_j \right ), \end{aligned}$$
where $\prod_{j \neq k} \left( 1 - | \mathbf{x}_{l} - \mathbf{c}_{i,l}(\mathbf{x}) |_j \right )$ and the differences between the hash table entries are constant to the $x_k$, which make ${\partial {\mathbf{h}_{l}}(\mathbf{x})} / {\partial {x}_k}$ is constant along with the $k^{\text{th}}$ axis of the unit hypercube. Notice that the last term can be seen as the weights defined as:
$$ \begin{aligned} \sum_{i=1}^{2^{d-1}} \prod_{j \neq k} \left( 1 - | \mathbf{x}_{l} - \mathbf{c}_{i,l}(\mathbf{x}) |_j \right ) = 1,\end{aligned}$$
where ${\partial {\mathbf{h}_{l}}(\mathbf{x})} / {\partial {x}_k}$ is the convex combination of the differences between two hash table entries.
Therefore, we change the original interpolation to have infintie-differentiable smooth gradient using cosine function,
$$\delta(w_{i,j}) = \frac{1-\cos(\pi w_{i,j})}{2} \quad \nabla_{x} \delta(w_{i,j}) = \frac{\pi}{2} \sin (\pi w_{i,j}) \cdot \nabla_{x} w_{i,j} $$
where $w_{i, j}$ is the weight for the $i$-th corner and the $l$-th level resolution.
Straight-through forward function
Furthermore, since the non-linear interpolation can hinder the original performance of the NGP, we propose to use the mix-up of tri-linear interpolation and smooth gradients:
$$\hat{w}_{i, j} = w_{i,j} + \lambda \delta(w_{i,j}) - \lambda \tilde{\delta}(w_{i,j})$$
where $\lambda$ is a hyper-parameter, denotes the detached variable from the computational graph.
Experiments
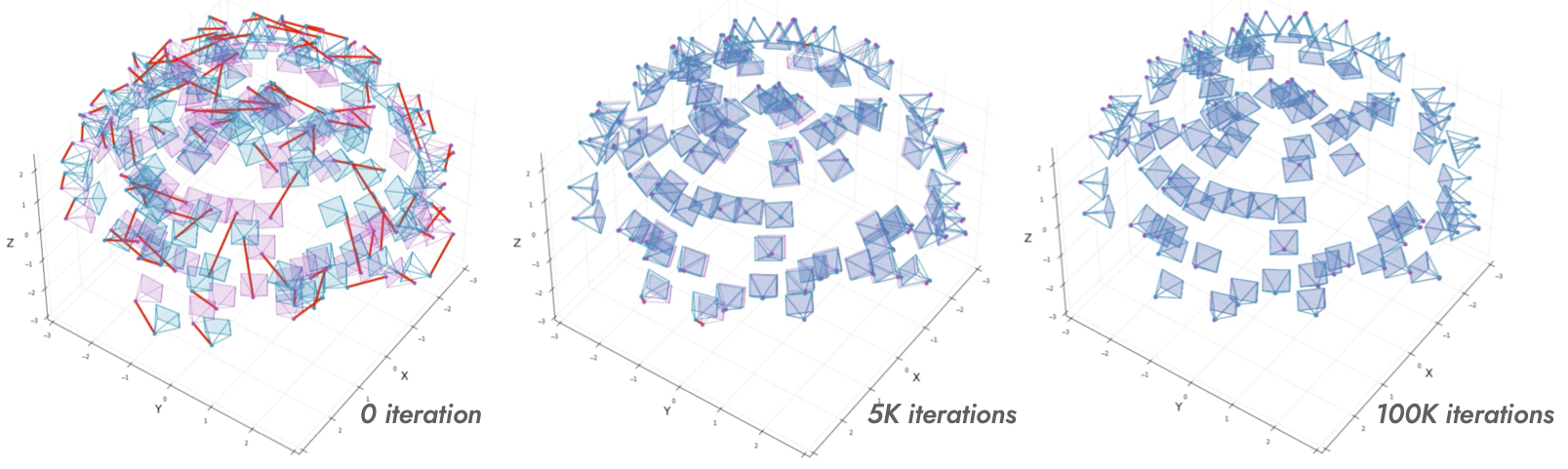
Visualization of the progress of pose refienments
Red lines denote pose error vectors between GT camera poses and optimized poses.
Training time per iteration
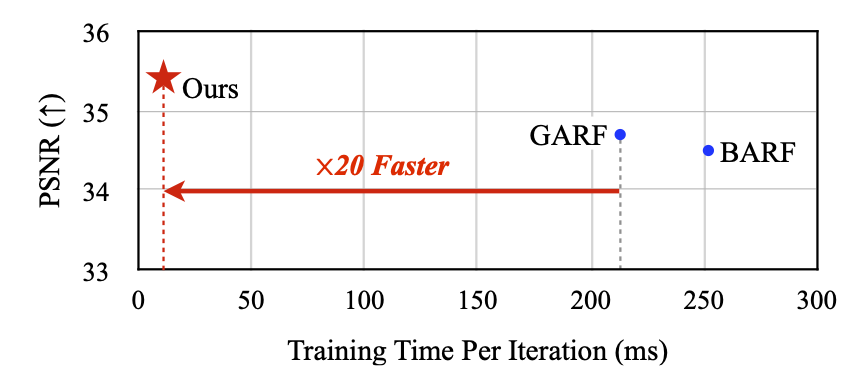
- Inherit Instant-NGP's faster convergence
- Inherit Instant-NGP's better accuracy
- Improve stability of pose refinement
Quantitative Results
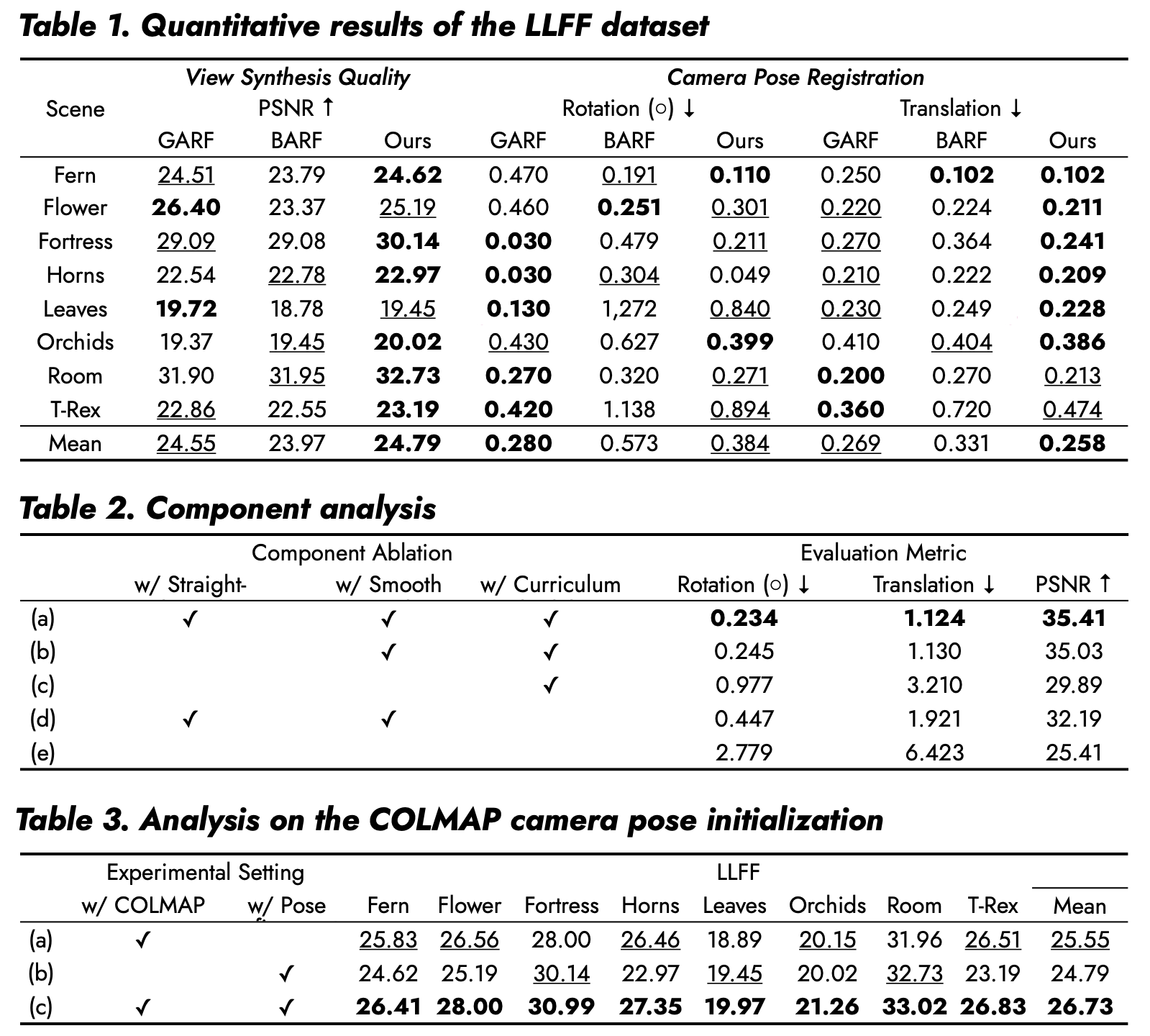
For the Synthetic (Blender) dataset, our reimplementation using tiny-cuda-nn and ngp_pl achieved a score of 31.54, compared with the paper's reported score of 29.86 and the GARF/BARF baselines at 28.96 and 28.84.