TL; DR

In this article, I will explore the capabilities of 3D reconstruction through Neural Rendering techniques (NeRF and 3D Gaussian Splatting) by analyzing a video generated by OpenAI’s recently released Video Generation AI, Sora.
The goal of the project includes examining the geometric consistency of Sora’s output and reflecting on the implications for the future of AI in video generation.
Introduction
Sora represents a groundbreaking development in AI, comparable to the impact of ChatGPT. While overcoming the curse of dimensionality in machine learning is notoriously challenging, I initially believed it would take a significant amount of time for video generation models to achieve performance levels similar to those seen in 2D image diffusion models.
However, a study from early 2024 has proven this assumption wrong. The following video provides a glimpse of Sora's remarkable capabilities:
This video showcases a substantial improvement over previous video generation models, which often struggled to maintain consistency even between frames. The smoothness and continuity in Sora's output indicate a new level of sophistication in video generation.
Can Sora understand 3D?
Given my background in 3D reconstruction, I became curious about whether Sora generates scenes with an understanding of geometric consistency or merely maintains content consistency. To explore this, I formulated the following hypothesis:
- Hypothesis: If Sora demonstrates a robust understanding of 3D geometry, then its generated outputs should facilitate accurate 3D reconstruction using computer vision techniques.
To test this hypothesis, I adopted a method similar to Novel View Synthesis from real-world capture, which involves:
- Capturing the video.
- Camera pose tracking (calibrating extrinsic and intrinsic parameters).
- NeRF Training for 3D reconstruction.
Experiments
I selected four videos from Sora’s published examples as candidates for 3D reconstruction:
| Big Sur | Santorini |
|---|---|
| Art Museum | Gold Rush |
These scenes were chosen based on their relatively static nature, as scenes with too many dynamic objects would complicate reconstruction.
Structure-from-Motion from Sora
After downloading the videos, I sampled the frames and performed Structure from Motion (SfM) using COLMAP. This process allowed us to assess how well Sora's output aligns with 3D geometry as assumed by stereo vision.
COLMAP is a computer vision tool that identifies image features (such as edges), performs feature matching, and utilizes bundle adjustment to determine the spatial positions of each frame.
The COLMAP results are as follows:
Santorini

COLMAP reconstruction from Sora: Santorini Museum
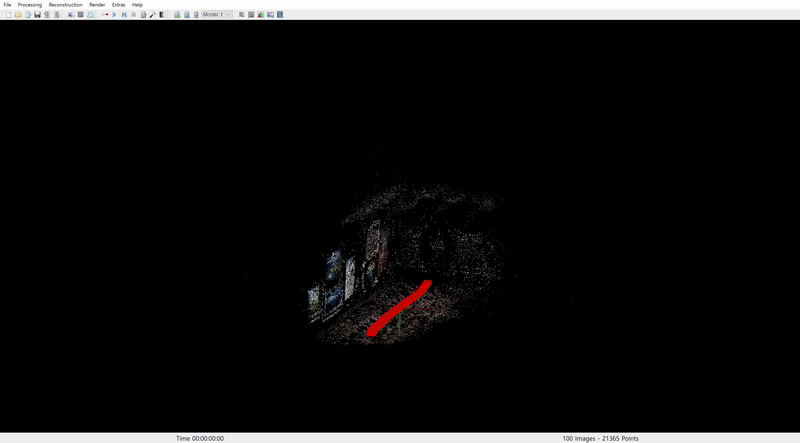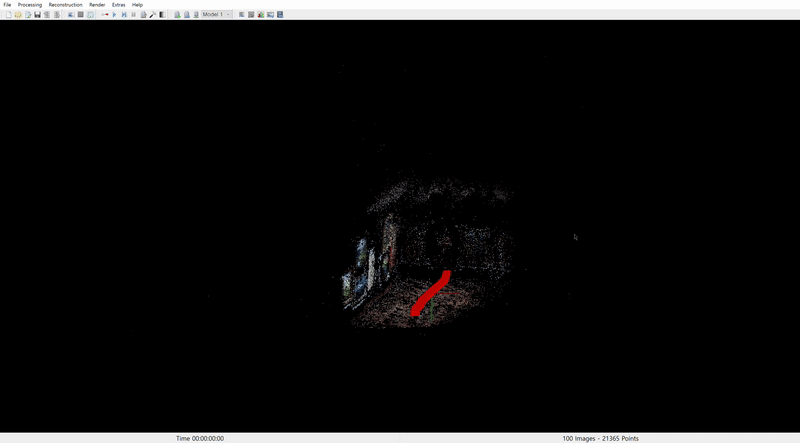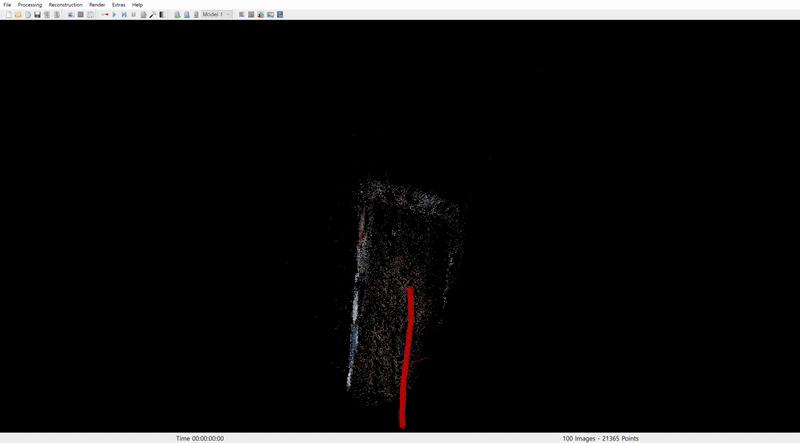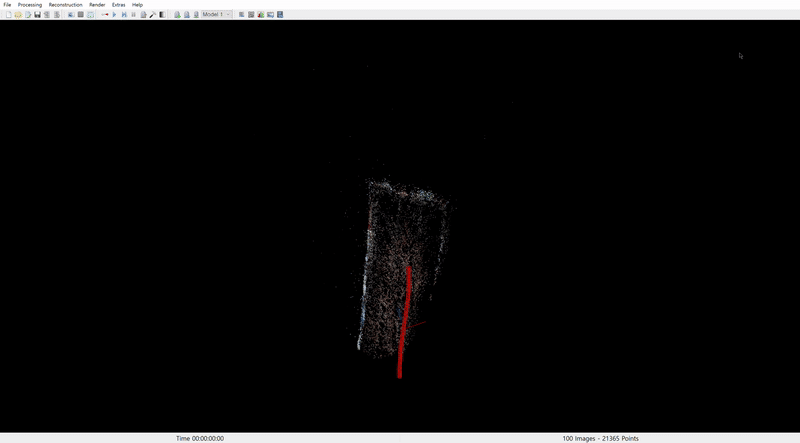
COLMAP reconstruction from Sora: Museum
In both cases, camera pose alignment was achieved to some extent. However, the results suggest that Sora does not fully comprehend 3D geometry. It appears to stretch existing landscapes to maintain content consistency rather than accurately represent 3D structures, as seen in the museum scene where the rectangular space is not properly reconstructed.
Compared to previous video generation methods that struggled with even content consistency, Sora shows enough geometric consistency to allow for convergence below a certain error threshold during bundle adjustment, which relies on stereo vision (epipolar geometry). It is also noteworthy that the COLMAP process took longer than usual, likely due to the time required to align features that do not perfectly match in 3D.
NeRF Reconstruction
Using the camera poses obtained from COLMAP, I proceeded with NeRF reconstruction. The results indicate that NeRF can successfully reconstruct the view for the visible portions of the scene.
Big Sur
Santorini
Museum
GoldRush
3D Gaussian Splatting Reconstruction
In addition to NeRF, I performed 3D reconstruction using 3D Gaussian Splatting (GS) based on the COLMAP sparse point cloud.
- 3D GS is characterized by lower reconstruction quality in scenes with image distortion or misalignment compared to NeRF. This is because, unlike NeRF, which can learn to smooth out misaligned images due to the inherent smoothness of MLP (Multi-Layer Perceptron), 3D GS is an explicit method that does not offer this capability.
Thus, the results from 3D GS provide additional insight into Sora’s ability to understand 3D geometry beyond what is visible with COLMAP and NeRF alone.
Big Sur
Santorini
Museum
GoldRush
While the qualitative quality between NeRF and 3D GS does not differ significantly, there are notable discrepancies in the Santorini scene, where the geometry is significantly off. Additionally, individual splats become visible when zooming into scenes reconstructed with splats.
Closing
In summary, Neural Reconstruction from Sora shows
- Geometric Consistency
Sora still lacks full geometric consistency (3D) in its generated outputs. - SfM Performance
Despite this, SfM is sufficiently consistent to operate effectively. - Human Perception
Neither Sora's nor NeRF/3D GS's outputs appear particularly strange when viewed normally. This may be because humans focus more on the content within and between scenes rather than attempting to form a perfect 3D geometric understanding. - Future Potential
If video generation can consistently maintain content consistency, I believe geometric consistency will eventually be resolved. This is because real-world 3D shapes tend to be efficient and familiar.
Given that this is just the first generation of Sora, its current performance is impressive. I am optimistic that within one or two more generations, models like Sora could generate videos that can be seamlessly reconstructed through neural rendering technologies for use in applications such as gaming. As a researcher, it is both exciting and humbling to witness such rapid progress, and I will be closely following OpenAI's advancements.
You may also like,
- A Comprehensive Analysis of Gaussian Splatting Rasterization
- Under the 3D: Geometrically Accurate 2D Gaussian Splatting