Introduction
I have never been particularly adept at documenting personal reflections. Nevertheless, 2025 brought far too many changes to dismiss as merely another year passing. It was a year in which I experienced the sensation of my life's trajectory being abruptly twisted—both professionally and personally. In particular, the spin-off of 'NC AI' as an independent entity and the technical and organizational upheaval I encountered throughout that process became a defining catalyst that fundamentally redefined the direction of my work. I would like to begin this piece by reflecting on the year alongside that record.

- Generated by Varco3D, NC AI's proprietary 3D Generative Model
Records Leading Up to Early 2025
'NC AI,' where I am currently employed, was originally a research division under NCSOFT. The peculiar structure of a massive 200-person research organization coexisting within a 4,000-person gaming company was something that, even as an insider, constantly raised doubts about its long-term sustainability. Especially before 2024, when the organization's direction remained ambiguous, my time there felt closer to stagnation than growth.
Despite the label of 'AI Research Lab,' research outcomes were disconnected from practical applications, and points of contact with actual product development were sparse. To alleviate the frustration born from this void, I began dedicating myself to external side projects starting mid-2024. To be frank, this was both preparation for a career transition and a form of escape.
In November 2024, just as I was contemplating leaving and with my mandatory military research service basic training imminent, news of NC Research's spin-off arrived. The organization was engulfed in a wave of departures that could aptly be called an 'exodus.' Swept along by the chaotic current of daily farewell announcements, I too cast applications to various companies in search of an exit.
Yet in the midst of this turbulent spin-off, I encountered an unexpected inflection point: the leader of my current team, who had been conceiving a 3D generation service in a different department within the company. His distinctive execution capability, honed through startup founding experience, and his attitude of transforming crisis into opportunity left a powerful impression. Above all, his vision of 'actually turning 3D generative AI into a real service' presented a clear direction to someone like me, who had been wandering between research and reality. For the first time, I thought, 'With this team, I could achieve something essential that I had never experienced at NC.'
Standing at the crossroads of leaving versus staying, my anguish deepened as acceptance letters and job offers arrived. Moving to the new team could quench my thirst for vision, but it was difficult to ignore the practical differences in conditions compared to external offers. After much deliberation, I requested a meeting with the executive leadership, where I confirmed the possibility of satisfying both technical challenges and reasonable compensation. And so, I joined the 3D generative AI service development team and immersed myself in generative model research.
1. Back to 2024
Before discussing Varco3D in earnest, I want to first lay out the technical background. Let us travel back to 2024, when 3D generation research was in its nascent stages, and examine the research trends and the evolution of internal projects at that time.
1.1 Non-Native 3D Generation
Prior to 2024, '3D generation' was advancing primarily through optimization-based methods led by SDS (Score Distillation Sampling).
The success of 2D image generation models, represented by Stable Diffusion, led to the hypothesis that '2D models might inherently understand 3D information.' Combining this with NeRF (Neural Radiance Fields), SDS became an irresistibly compelling research topic. The fact that optimization-based methods required relatively fewer GPU resources to generate a single asset was also an advantage that made it easily accessible in resource-constrained research labs.
At that time, there was a prevailing perception in the gaming industry that pure reconstruction research (NeRF/GS) would be difficult to translate into actual productivity. Consequently, aligning with the SDS trend, the entire team's research direction was reorganized toward '3D generation.' However, overcoming the inherent performance limitations of SDS through loss term design alone proved difficult. SDS can be viewed as forcibly constraining a well-trained 2D Diffusion (or Flow) model to act as a mode seeker, which caused the following problems:
- Saturated Color: Due to the use of high CFG scale to enforce mode seeking
- Janus Problem (multi-face problem): Frontal bias of 2D models & lack of multi-view consistency

- Slow speed: Because generating an asset requires hundreds of 2D model inferences while updating NeRF or 3D Gaussian Splatting (GS)
- Noisy Geometry
As SDS research progressed, issues like color saturation and the Janus problem were somewhat alleviated, but geometric quality and speed remained challenging. In particular, even the results of 'Dreamcraft3D'—which was SOTA at the time in 2024—showed dismal geometry quality when converted to polygonal mesh, starkly demonstrating SDS's limitations.

The cause of these problems can be traced to SDS's optimization objective.
$$ \nabla_{\theta} \mathcal{L}_{SDS} \approx \mathbb{E}_{t, \epsilon} \left[ w(t) ( \underbrace{\epsilon_{\phi}(x; y, t) - \epsilon}_{\text{Guidance Term (Residual)}} ) \frac{\partial x}{\partial \theta} \right] \\ \text{where } \theta : \text{3D model, } x : \text{rendered image} \\ {} $$
$$ \frac{\partial C}{\partial \theta} = \underbrace{\frac{\partial C}{\partial c} \frac{\partial c}{\partial \theta}}_{\text{Color update}} + \underbrace{\frac{\partial C}{\partial \sigma} \frac{\partial \sigma}{\partial \theta}}_{\text{Geometry update}} \\ {} \\ \rightarrow \Delta \sigma \propto (\epsilon_{\phi} - \epsilon) \cdot \frac{\partial C}{\partial \sigma} $$
When updating a 3D model with SDS loss, following the chain rule reveals that the update terms for texture and geometry are not separated. As a result, high-frequency noise from the 2D model is directly transferred to the geometry update, causing the mesh surface to appear extremely rough when viewed without texture.
Remarks on Noisy Geometry
a. Whether you choose NeRF or GS as the 3D representation for SDS, converting either representation to a clean mesh is itself an extremely difficult problem.
b. Using NeRF or GS directly without converting to a polygonal mesh also presents many problems. Although many engines support GS rendering, features like deformation, rigid body setup, and collision detection are incomparable to mesh in terms of performance and stability.
1.2 Texture Generative AI
Around the same time, another team within the company was researching Texture Copilot, which generates and edits the texture of polygonal meshes using 2D generative AI.
NC Research Blog: Texture Copilot
This approach involved rendering a given mesh as depth and normal maps from multiple angles, then using ControlNet to generate multi-view images and back-projecting them onto the mesh.

- Visualization of multi-view images back-projection on mesh
It was an innovative approach and achieved results that were applied to actual game development pipelines. However, it had drawbacks such as the Janus problem caused by the frontal view bias inherent in 2D models, and the service's inherent requirement for pre-existing geometry.
1.3 Beyond SDS; Native 3D Generation
Around that time, on another axis of 3D generation research, 3D diffusion model research using 3D Native VAE was expanding. This approach, represented by 'VecSet VAE,' is a VAE structure that compresses point clouds sampled from polygonal meshes into a latent space and then reconstructs an SDF field from that space. (For details, refer to The Era of 3D Generative Models)
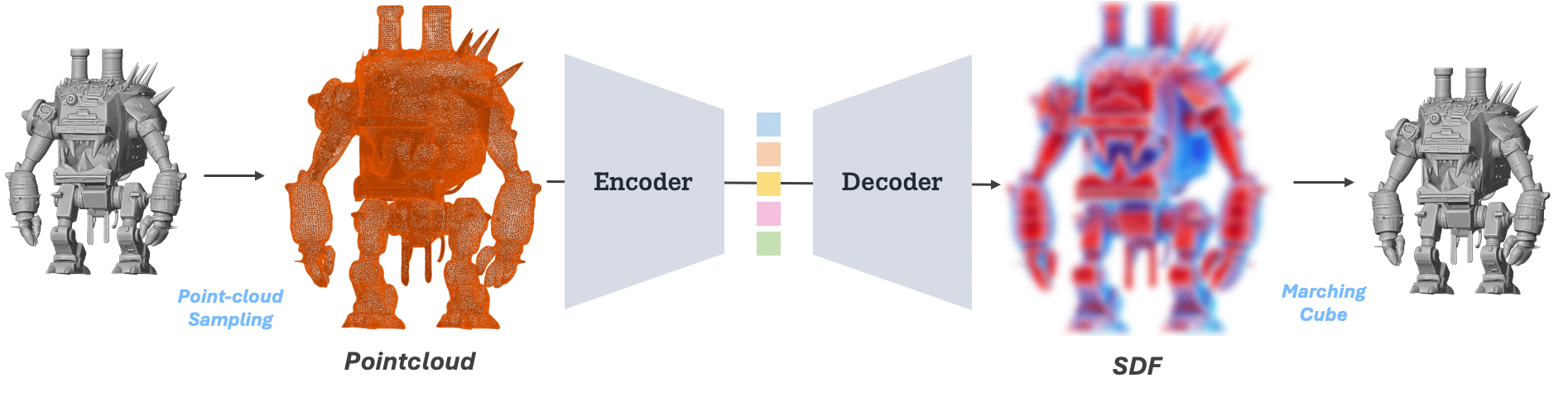
- ShapeVAE illustration
Through such ShapeVAE, training a Diffusion Model or Flow Matching model from a latent space that compresses meshes with hundreds of thousands of faces into roughly 2K–8K token length is the basic framework of '3D Native Generative Models.'

- Sample results from Direct3D, one of the 3D DiT models trained on ShapeVAE
I judged that by combining this 3D native geometry generation research with the ideas from Texture Copilot, it would be possible to build a complete pipeline that circumvents SDS's chronic problems. Based on this belief, at the end of 2024, I undertook the CaPa project, which involved directly training ShapeVAE and DiT models, as well as designing attention modules for multi-view generation to solve the Janus problem in texturing.
Working on this project, I became convinced that optimization-based 3D generation methodologies would eventually reach their limits. DiT based on ShapeVAE is a feed-forward method, making it much faster for asset generation than SDS, and scaling up the DiT model size allows extending the success of scaling laws to the 3D domain.
2. Pursue SOTA: 3D Sovereign AI
2.1 Varco3D-alpha
After moving to the new team, my first task was to expand the CaPa pipeline and launch Varco3D-α, our in-house 3D generation service. The model architecture followed a typical 3D generation pipeline inherited from CaPa.
- Geometry Generation: ShapeVAE + DiT
- Texture Generation: Multi-View Image Synthesis to Mesh Back-projection, leveraging 2D Generative Models
One important intuition I gained while training this model was that training a 'Geometry VAE' requires far less data and resources than 2D generative models. This is based on the assumption that the distribution of 3D geometry is simpler than that of RGB images. Indeed, artist-crafted polygonal meshes, unlike RGB images, do not have much variation in high-frequency details or complex backgrounds.
Additionally, high-performance open-source models at the time were unavailable for commercial use due to licensing issues. This background became the catalyst for forming an internal consensus that 'we must continuously advance our own models.'
cf. Denoising process visualization; Varco3D-α (Rectified Flow Model)
| Dragon Head | Steampunk Machine |
|---|---|
 |
 |
2.2 SOTA Sparse Voxel Method
After the alpha release, the team encountered a significant technical inflection point. Methods based on sparse voxels (sparse grid-based) emerged, demonstrating overwhelming detail compared to existing VecSet-based approaches.
In particular, Microsoft's Trellis and the subsequent Sparc3D delivered a significant shock, showing a resolution (LoD) difference of two or more levels compared to previous models.
| Hunyuan3D 2.5 | Sparc3D |
|---|---|
 |
 |
At that time, observing Hunyuan 3D 2.5—a 10B-scale model released before Sparc3D—I believed that high-quality mesh generation was a domain achievable only through scaling laws.
However, Sparc3D proved that by actively adopting sparse operations, it was possible to train high-quality mesh generation models at low cost. (While VecSet VAE took more than two weeks to converge on 32 A100 GPUs, Sparse Voxel VAE was sufficient in just two days.)
Why does such a difference arise?
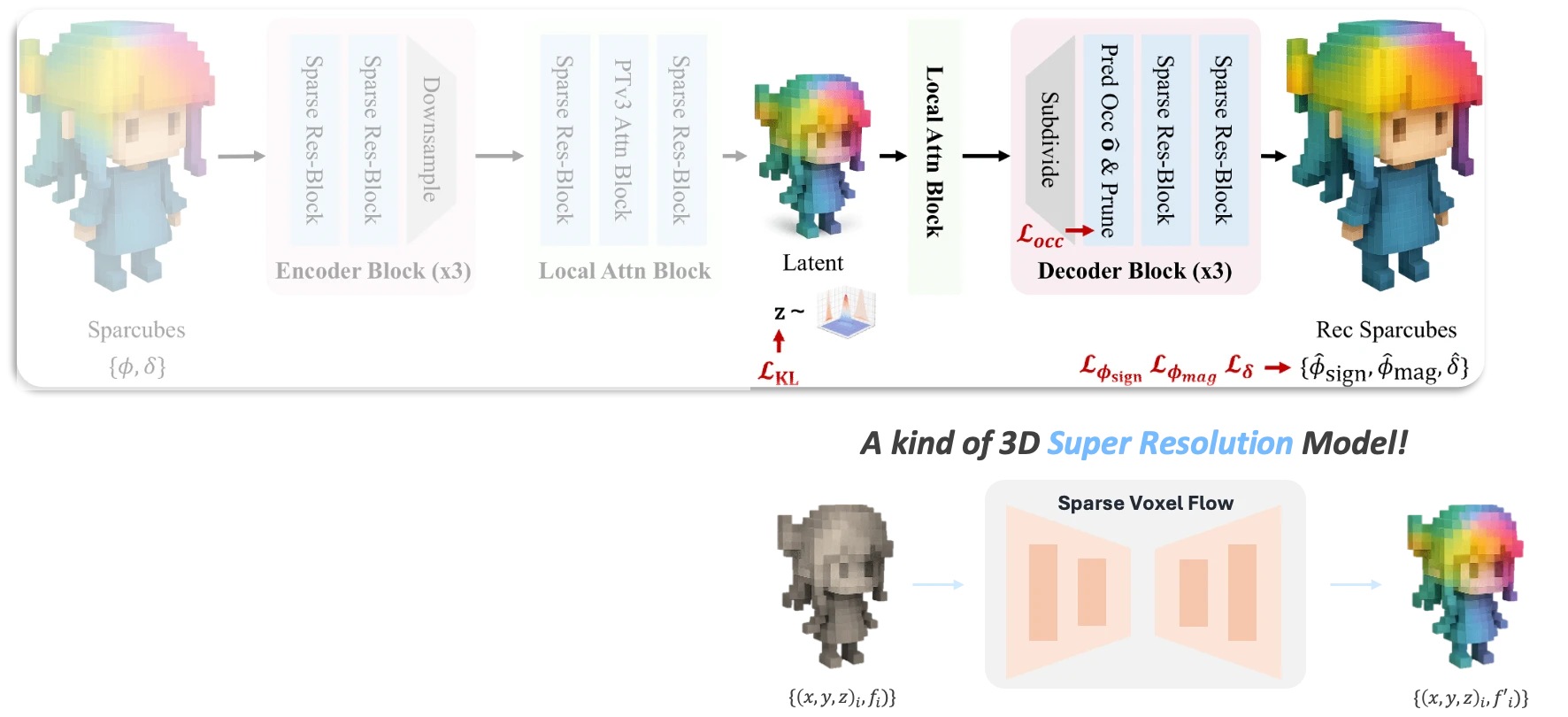
- Reconstruction of Sparc3D's inference pipeline illustration
The secret behind this performance difference lies in the structural characteristics. As shown in the figure, the decoding of Sparse Voxel VAE maps a low-resolution sparse voxel latent grid to a high-resolution sparse voxel SDF grid. In other words, sparse voxel VAE is essentially a form of '3D super-resolution.'
In this structure, instead of creating the overall shape, the generative model (DiT) focuses on recovering fine details within already-defined active voxels. By decoupling global shape and detail generation, training efficiency could be dramatically maximized.
Remember the assumption of 'when the information of active voxels is known.' This means another model is needed to handle global shape generation.
Under this potential, reimplementing Sparc3D to secure a SOTA-level 3D generation model became our goal for the second half of 2025.
2.3 Varco3D 1.0-preview
Upon deciding to switch geometry generation to a sparse voxel basis, the core challenge we faced was:
'Who will be responsible for generating active voxels?'
As mentioned earlier, sparse voxel-based 3D generation models are essentially 3D SR models, so a method was needed to generate the 'input for SR'—that is, approximate global shape information.
Trellis, which pioneered the direction of sparse voxel-based 3D generation, uses a separately designed model for this purpose. However, to use this model for mesh generation at resolutions of $1024^3$ or higher rather than the existing $256^3$, the resolution of active voxels also needed to be raised to the $128^3$ level, which caused serious computational issues.
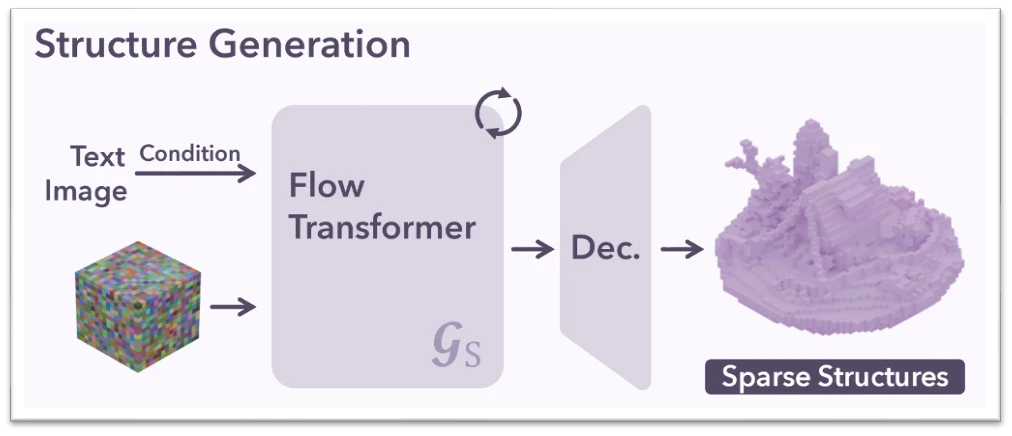
In Trellis's model formulation, this is equivalent to training and inferring a diffusion-based model on a dense voxel grid of $32^3$. In other words, it's a model with full attention cost of $32^3 \times 32^3$, or $1M$ tokens, and training this with our resources at the time was nearly impossible.
At this point, I proposed the idea of 'voxelizing the coarse mesh created by Varco3D-α (VecSet) and using it as input to the DiT.' This strategy was to leverage the already-proven global shape generation capability of the VecSet model while circumventing the high-resolution computation problem. (By the time of this writing, this has already become a common idea.)
| Coarse mesh from Varco3D-α | its voxelized ($128^3$ resolution) |
|---|---|
 |
 |
For this, I implemented a CUDA kernel that computes the distance between mesh and voxel centers in parallel, and as a result, I was able to reduce the process from coarse mesh generation to active voxel generation to under 5 seconds.
After solving this and various other issues, and successfully training on AWS's 64 A100 GPUs (8 multi-node), we were able to present Varco3D 1.0-preview—our own sparse voxel-based 3D generation model—around November 2025.
Below are the results of Varco3D 1.0-preview, a sparse voxel-based 3D generation model.

3. Back to VecSet
3.1 Lattice
Do you remember that sparse voxel-based methodologies (Sparc3D, etc.) dramatically improved training efficiency and quality by separating global shape and local detail generation?
Lattice is the core structure behind Hunyuan3D 2.5/3.0's geometry generation model released by Tencent. Like Sparc3D and others, it applies a two-stage approach to the VecSet methodology—first generating a global shape, then using that result as guidance to generate local details. (In fact, considering the release timing of Hunyuan3D 2.5, it appears that Tencent internally validated and completed training on the coarse-to-fine structure much earlier than research like Sparc3D)
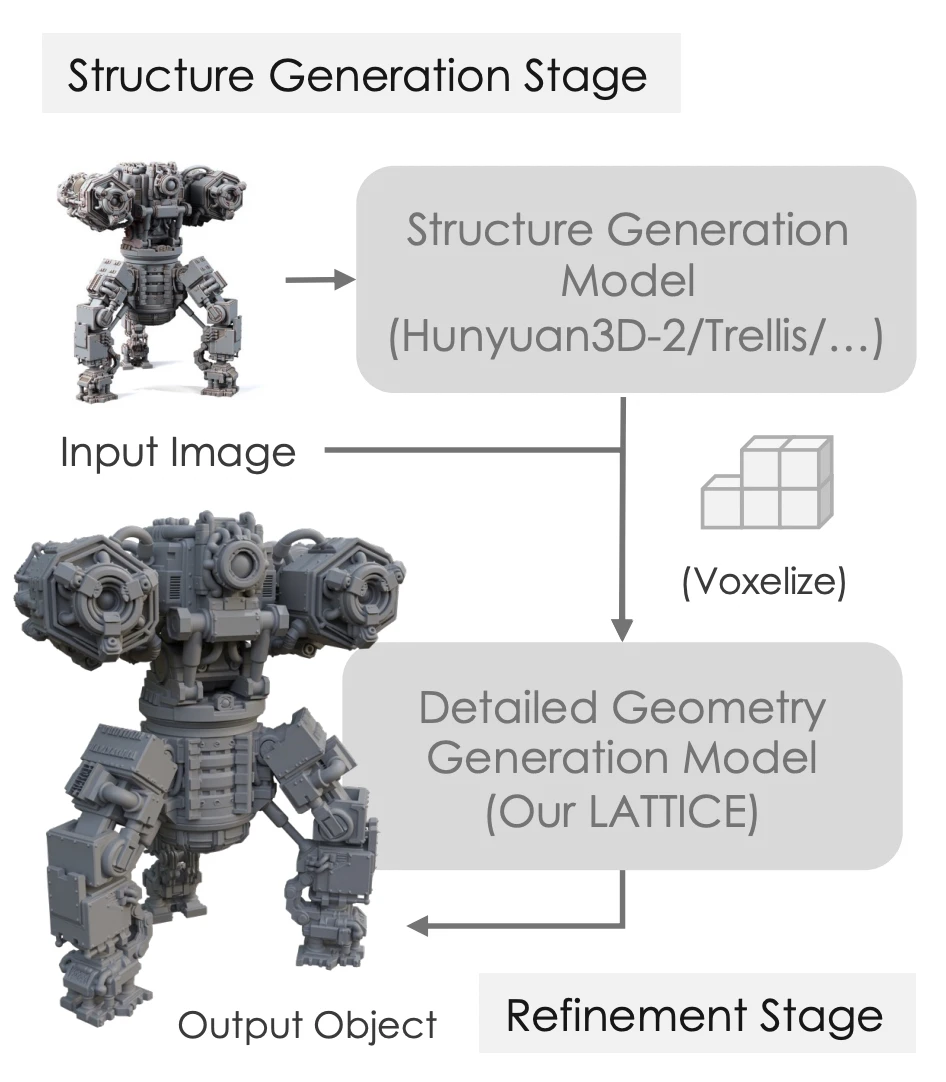
Specifically, it consists of the following two-stage pipeline:
- Coarse Generation: Generate a coarse mesh using existing VecSet models, etc.
- Voxelize & Sampling: Voxelize this, then extract representative points within each voxel through FPS (Farthest Point Sampling).
- Structure-Aware DiT: Use the coordinates of these points as 'Voxel Query' and apply RoPE (Rotary Positional Embeddings) to the coordinate information before inputting to the DiT.
${}$
3.2 FlashVDM; Vice-Versa of Lattice?
I speculate that the idea for this paper originated from experiments in FlashVDM, a study on accelerating VecSet decoding (the authors are also the same). FlashVDM proposed octree-decoding (Hierarchical Decoding) for the existing VecSet decoding stage, which required dense grid point queries for SDF extraction, reducing decoding time by tens of times.

- Visualization of FlashVDM. When reconstructing the mesh on the Right through the VAE decoder, FlashVDM first identifies active voxels at a coarse resolution (Left → Right), then increases resolution only within the range of these active voxels to reconstruct high-resolution SDF.
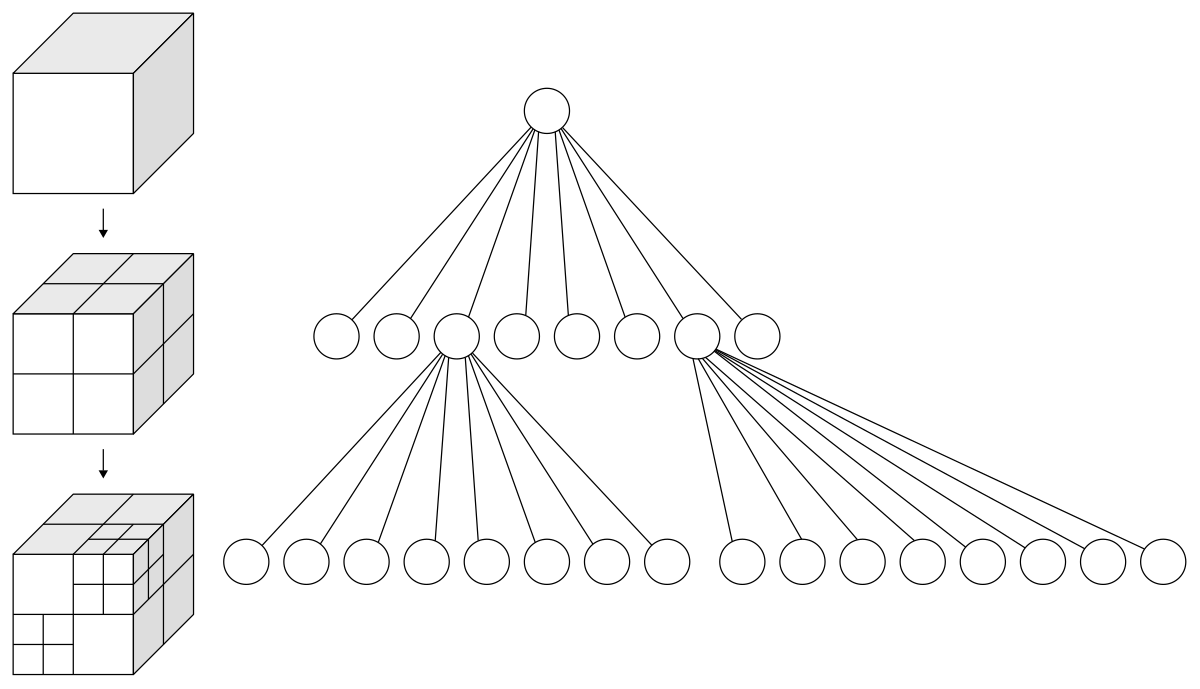
Beyond octree-decoding, an important characteristic of VecSet VAE reported in FlashVDM is that when the VecSet VAE Decoder receives point queries to decode SDF values, spatially adjacent point queries focus only on attention with similar latent tokens. Reversing this discovery leads to the conclusion that VecSet's latent tokens already have a close relationship with spatial location and inherently possess strong locality.
This leads to the assumption that if positional information is provided correctly, fine details can be filled in without needing to relearn the entire structure. In other words, if we can convey the connection to 3D spatial location when training/inferring the DiT model, we can design a refinement model that knows information about the global shape, just like sparse voxel methodologies. The DiT doesn't create shapes from scratch in empty space, but rather focuses only on local detail generation while receiving strong guidance about the global shape.
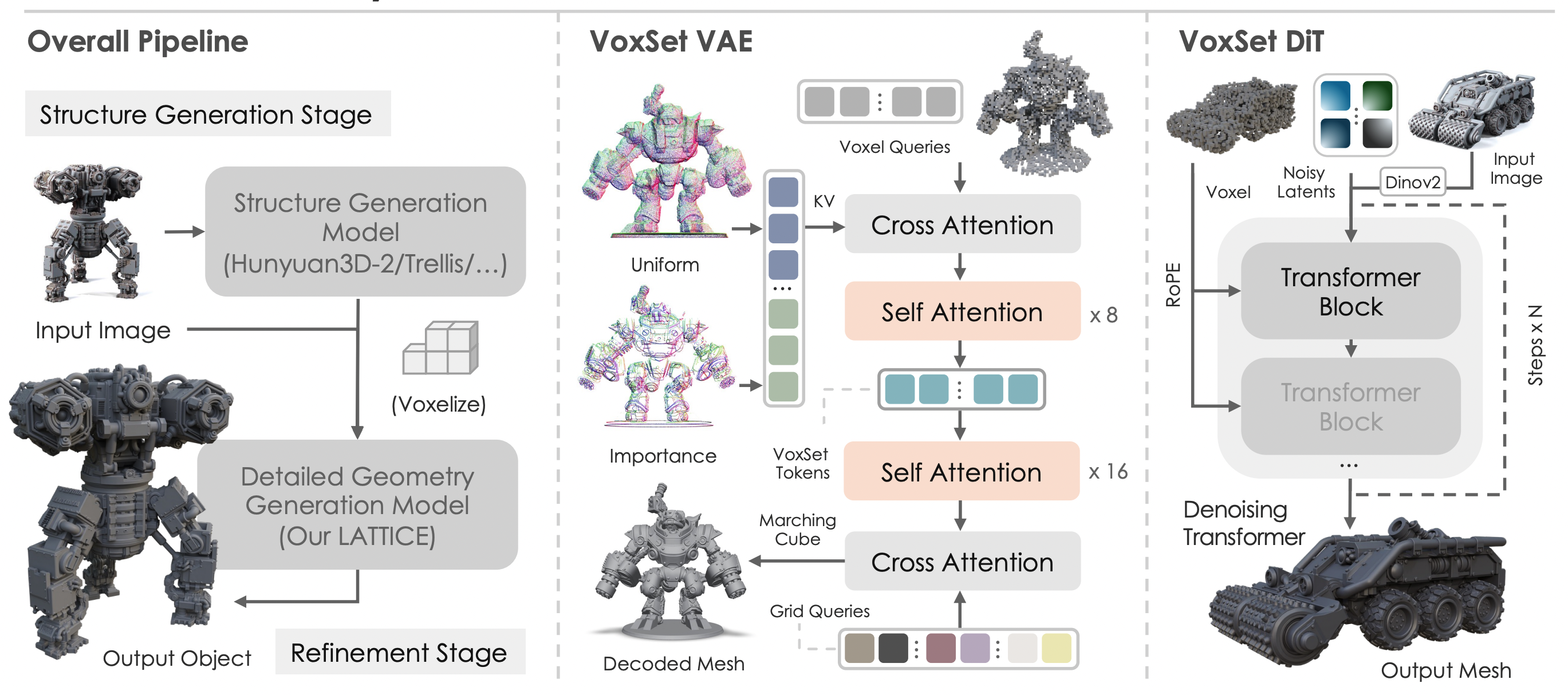
Lattice drastically shortened training efficiency and enabled a coarse-to-fine structure in VecSet by voxelizing the coarse mesh, then injecting the sampled representative coordinates through RoPE embedding.
There are also incidental benefits of voxelization. While existing VecSet accepts 'any point coordinates' in space as input, voxelization causes RoPE embedding to concentrate on points on a regular grid, significantly reducing the search space for the generative model. By providing inductive bias, the model rapidly acquires spatial prior knowledge.
3.3 Varco3D-Lattice
Based on the Lattice structure, I trained a Structure-aware DiT model by adding Voxel query RoPE to the Varco3D-α model architecture. The results were remarkable—unlike the existing VecSet DiT, which took over a month to converge on 64 A100 GPUs, the DiT model converged in just one day.
Below is a visualization of the high-quality mesh generation process through Varco3D-Lattice: 1) coarse mesh generation, 2) voxelize & voxel query sampling, 3) fine mesh generation.
| Coarse Mesh | Voxel Query | Fine Mesh |
|---|---|---|
 |
 |
 |
vs. Sparse-Voxel Method
It was encouraging that the model outputs showed detail equal to or better than Varco3D 1.0-preview (Sparse Voxel), while also demonstrating much more robust mesh topology and fewer artifacts. This model will be officially updated as the Varco3D 1.0 model after going through inference optimization.
Below are some comparisons with Varco3D 1.0 preview, which uses the same coarse-to-fine approach.

- Varco3D 1.0-preview (sparse voxel) vs. Varco3D 1.0 (VecSet-Lattice)
While the sparse voxel-based Varco3D 1.0 preview model also generates excessive detail and artifacts, the Varco3D 1.0 model produces clean and robust outputs.

- Varco3D 1.0-preview (sparse voxel) vs. Varco3D 1.0 (VecSet-Lattice)
4. Next Step in 3D Generation
As we enter 2026, I would like to conclude this piece by organizing my thoughts on the technical balance between 'Sparse Voxel' and 'VecSet' that I perceived during the Varco3D 1.0 development process, as well as the possibilities of new 3D representations beyond these.
4.1 Sparse Voxel vs. VecSet
For the time being, the contest for dominance between the Sparse Voxel and VecSet camps will likely continue. Having personally trained and served both models, I would summarize the pros and cons as follows:
Sparse Voxel
Advantage — Detailed Generation: Unlike Lattice, which samples via FPS, sparse voxel methods use all active voxels, often excelling over Lattice in terms of local detail.
Disadvantage — Instability: There are significant shortcomings in terms of training and inference stability. Token length varies for each piece of data, and the number of active voxels at $128^3$ resolution alone averages over 80K. Additionally, because all active voxels are used, the quality is highly dependent on the quality of active voxels.
At this token length, full attention training is practically impossible, so one must either use Sliding Window Attention like Swin Transformer or downsample to 64/32 resolution for full attention and then upsample again, which introduces structural instability in the process.
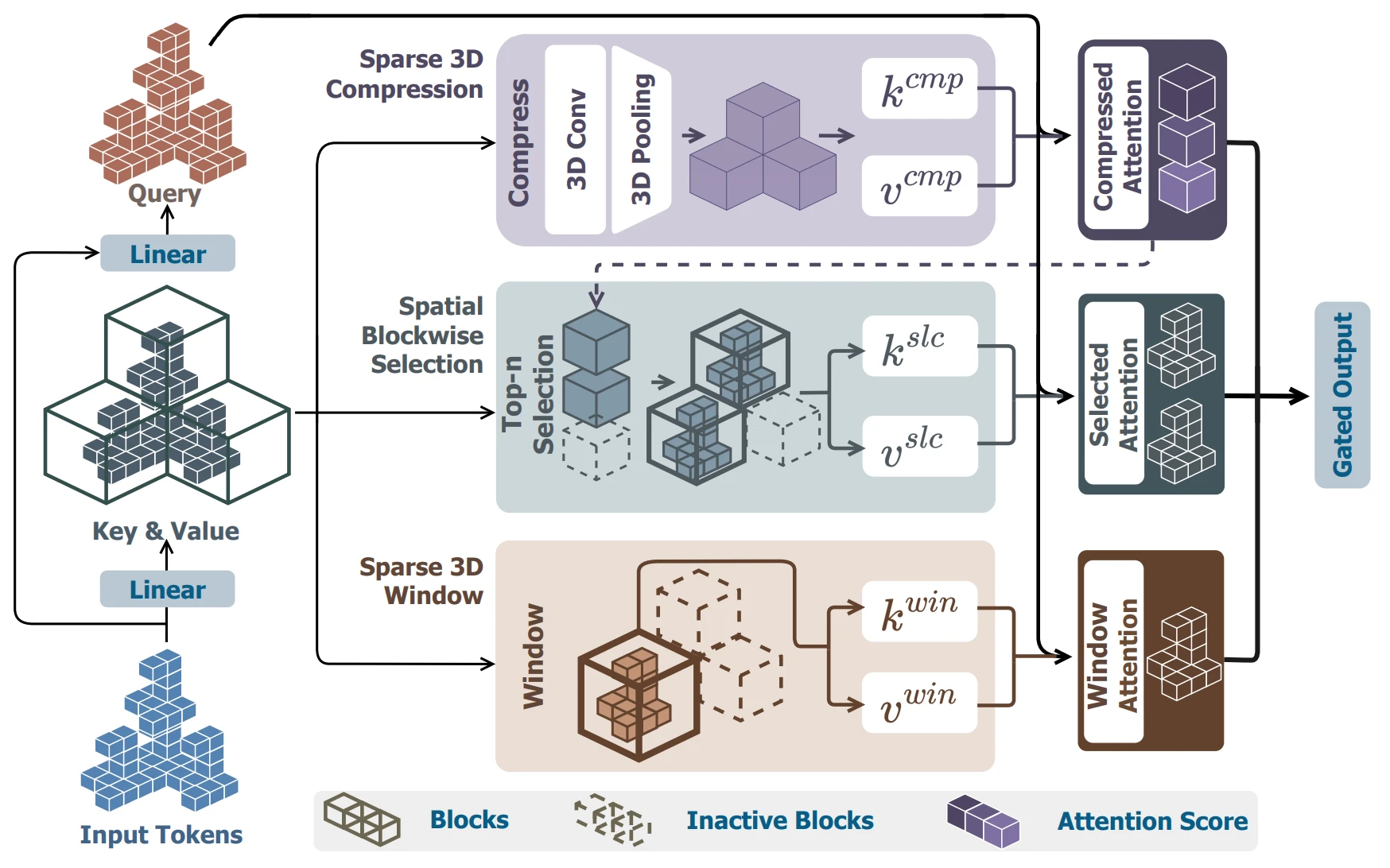
- Direct3D-S2's 3D sliding window attention mechanism
VecSet
Advantage — Full Attention: By adopting the Lattice structure, training is possible with far fewer tokens (approximately 6K), allowing full attention to be applied stably.
Advantage — Inference Time Scaling: The biggest advantage is the ability to perform inference time scaling by increasing the number of tokens to 32K or more to maximize detail. Since the number of tokens is not fixed in VecSet, more tokens can be used at inference time to obtain more refined results.
Disadvantage — Decoding Time: VecSet has a structure that requires querying all points of a dense grid to the decoder to reconstruct the 3D representation during decoding. While decoding time can be reduced with FlashVDM and similar methods, even then it takes several minutes for high-resolution meshes, which is longer compared to sparse voxel methodologies.
4.2 Beyond SDF: Trellis 2 & Faith-Contouring
Finally, what I am paying attention to in the 3D generation field in 2026 is the change in 3D representation itself.
All the methods described so far have been under the shadow of SDF (Signed Distance Function). SDF is a value that indicates how far a point in space is from an object's surface (Distance) and whether it is inside or outside (Sign). This is converted to a mesh through the Marching Cubes algorithm, but there is a critical constraint: 'it must be a closed object (watertight).' Since only sealed shapes that do not leak water can be represented, there were clear limitations in generating 'open surfaces' such as torn collar edges, thin paper, or cross-sections of transparent glass.
Recently released Trellis-2 and FaithC chose an approach where AI directly predicts QEM (Quadric Error Metric) parameters instead of predicting SDF values to solve this problem.
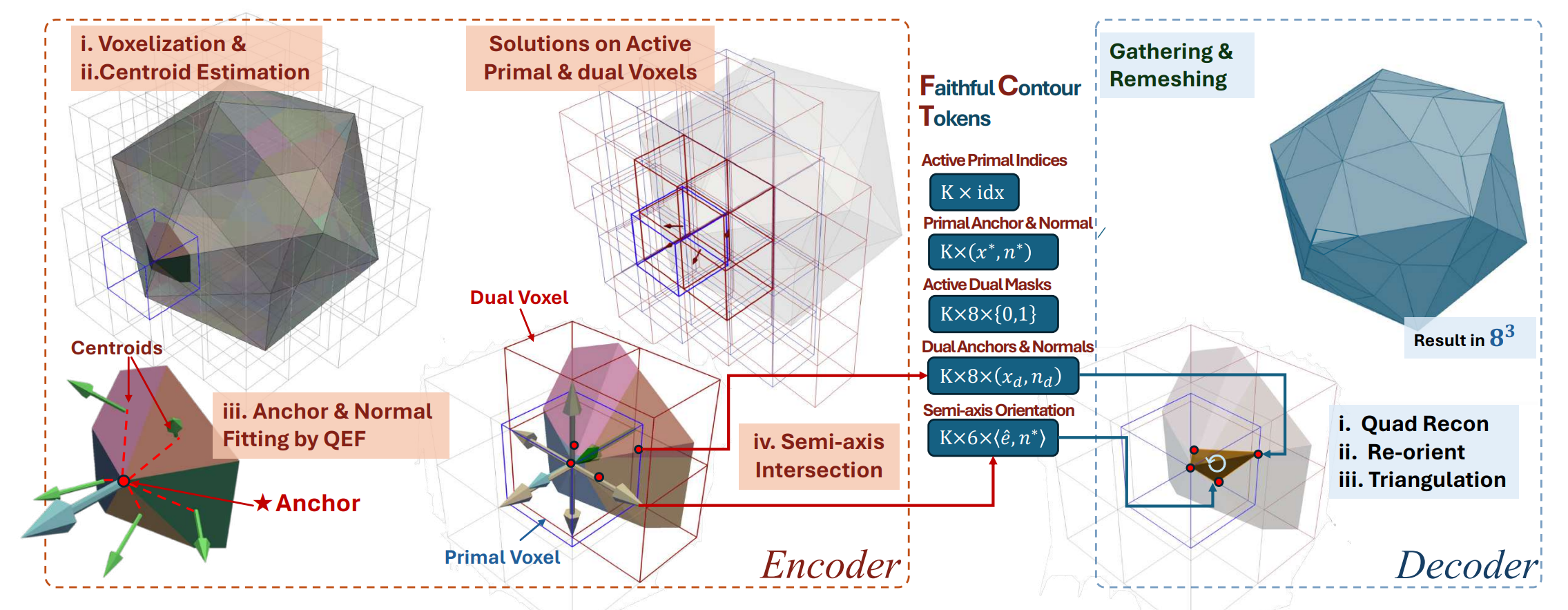
- Illustration of FaithC
Of course, there are clear trade-offs with this approach as well. The biggest problem I noticed through direct generation was 'topological discontinuity'—in simple terms, the phenomenon of results being torn. I believe this occurs because, with the strong continuity constraint of SDF removed, the predicted values of each voxel generated by the model fail to connect smoothly with each other.

- Generated by Trellis 2
Since SDF is mathematically defined in a 'continuous function' space, the surface is guaranteed to be smoothly closed regardless of resolution. However, methods like Trellis2/FaithC that predict values on a discrete voxel grid frequently produced artifacts such as holes in the surface or torn meshes when the model failed to perfectly learn the connectivity between adjacent voxels.
As an idea to solve this problem, one could consider predicting information that guarantees surface continuity, like UDF (Unsigned Distance Function), as an additional channel alongside the existing Q matrix. If we guide topological continuity between adjacent voxels through UDF gradients without forcing 'closed shapes' like SDF, I believe it might be possible to achieve robust native 3D generation that creates "open surfaces that don't tear" without post-processing.
Epilogue
As I conclude this piece, I want to share some honest reflections that have settled in a corner of my heart as a researcher.
Objectively speaking, the current Varco3D is still difficult to claim as superior when compared to closed SOTA models released by global big tech companies. Facing their capital power, which deploys thousands or tens of thousands of H100 GPUs, the reality of having to train models with 64 A100s sometimes brings a sense of helplessness. While saying "we lack resources" sometimes feels like a cowardly excuse, at the same time, anxiety rushes in when I find myself struggling just to keep up with the new research that pours out every morning.

- Varco3D-1.0 vs. Hunyuan3D-3.1 vs. Meshy-6
Yet this anxiety paradoxically leads to an intense yearning for 'pure research.' I want to answer fundamental questions—not simply being consumed with more efficiently following paths that others have paved, but rather exploring what the essence of 3D representation is, how to translate mathematical continuity into the language of deep learning. I believe that the 'practicality gap' that current 3D AI services cannot overcome can only be bridged by innovating the essence of 3D, such as representation methods, rather than by the size of parameters.
The reason for insisting on our own models under the grand slogan of 'Sovereign AI' is not simply due to licensing issues. It is the will to not merely be a follower tracing the footsteps of big tech, but to create a 'sharp crack' that changes the technological landscape from our own perspective. So that the limits of resources do not become the limits of imagination—in 2026 as well, I wish to remain someone who does not linger in the sensation of stagnation, but who pushes against the turbulent current.
- Varco3D 1.0
You may also like
- An Era of 3D Generative Models
- Building Large 3D Generative Models (1) - 3D Data Pre-processing
- Building Large 3D Generative Models (2) - Model Architecture Deep Dive: VAE and DiT for 3D